
AMD问题ADNC 4架构:HBM3E支持着重提高AI的负载能力
发布时间:2025-06-20 13:24
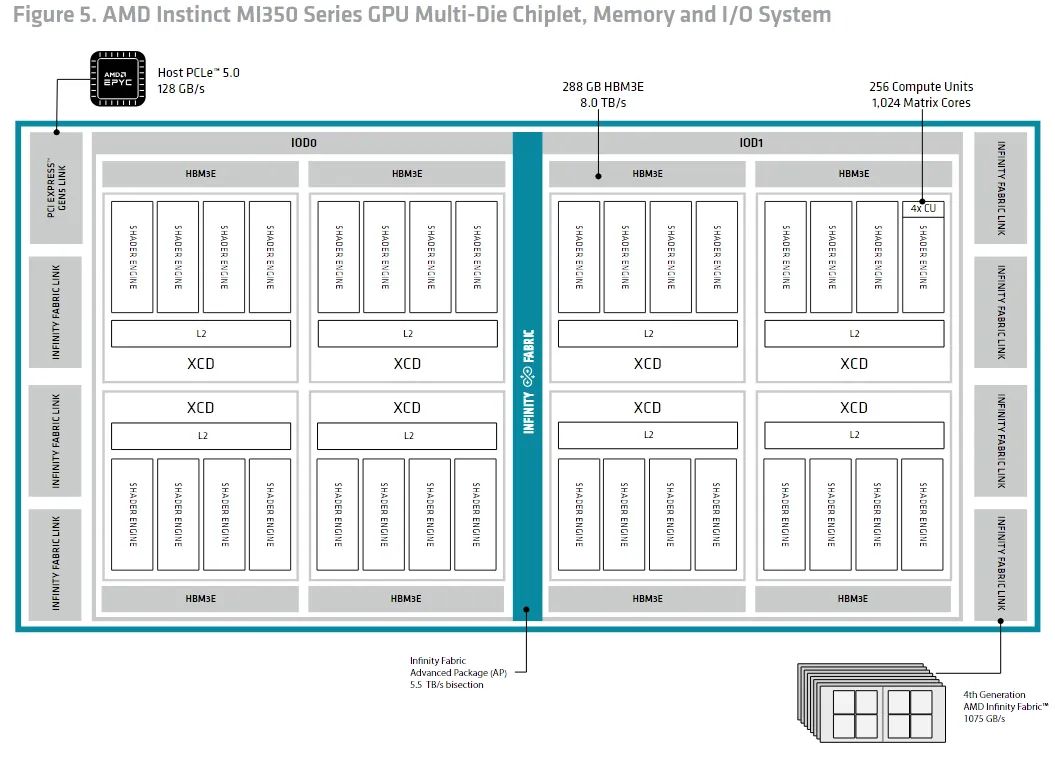 6月19日的新闻,技术媒体芯片沙奶酪昨天(6月18日)发表了一篇博客文章,该文章报道AMD已正式推出了其ADNA 4. Architecture。除了维持通用矢量计算领域的好处外,它主要集中于改善低精确数据类型的矩阵乘法的性能,从而提高人工智能工作量(AI)的处理能力。 ADNC 4继续具有ADNC 3的模块化设计,该设计使用类似于CPU的花栗鼠设计。每个计算芯片单元(XCD)配备了ADNC(CU)计算机单元,该计算机单元将八个XCD通过四个板芯片集成,形成一个完整的GPU体系结构,其中包括256 MB内存侧缓存。与ADNC 3中的MI300X相比,ADNC 4中的MI355X通过减少单个XCD中的CU和某些单元的CUS来提高性能,但以高时钟频率减少了性能差距。在计算低预测的关键指标中离子矩阵,ADNC 4将CU的每个矩阵的性能加倍,而FP6的精度性能与传输多处理器NVIDIA B200(SM)相同。但是,在8和16位数据类型之间,NVIDIA仍然保持单个周期收率的优势。但是,由于CUS的数量和频率很高,AMD在共同的矢量计算中保持绝对潜在客户(例如FP32)。单个CU仍然提供128 FP32计算机管道,其一般性能远高于NVIDIA Blackwell Architecture。 ADNC 4的核心改进之一是增加本地数据交换(LDS)的能力和带宽。 SUS容量从64 KB增加到160 KB,读数带宽增加了一倍,达到每个周期的256个字节,并且添加了“ transpos读取”指令,以优化矩阵乘法的命中式访问效率。 NVIDIA的共享内存具有单个缓存和缓存灵活性的出色容量(最多228 kb的共享内存)。 だったります)AMD弥补了中央级别缺乏存储,完全容量为40 MB LDS GPU(B200约为33 MB)。在视频内存方面,MI355X已更新为HBM3E技术,总计8TB/SY带宽的容量为288 GB,大大超过7.7tb/sy 180GB NVIDIA B200。在大型数据计算中,尤其是当AMD的体系结构可以减少数据交换中的延迟时,尤其是当AI模型超过内存容量时,这一优势尤其重要。媒体认为,AMD的ADUNC 4继续通过优化而不是破坏性的创新来整合收益,以及Zen的迭代逻辑。Strategy专注于增加计算机规模和内存带宽,同时瞄准AI缺陷。必须被认为重要的媒体是在提高性能方面的AMD和NVIDIA之间的差异。虽然AMD基于“大芯片 + Gran Cache”模型,但NVIDIA对该禁令更加关注视频记忆的单个核的昏迷和效率。
6月19日的新闻,技术媒体芯片沙奶酪昨天(6月18日)发表了一篇博客文章,该文章报道AMD已正式推出了其ADNA 4. Architecture。除了维持通用矢量计算领域的好处外,它主要集中于改善低精确数据类型的矩阵乘法的性能,从而提高人工智能工作量(AI)的处理能力。 ADNC 4继续具有ADNC 3的模块化设计,该设计使用类似于CPU的花栗鼠设计。每个计算芯片单元(XCD)配备了ADNC(CU)计算机单元,该计算机单元将八个XCD通过四个板芯片集成,形成一个完整的GPU体系结构,其中包括256 MB内存侧缓存。与ADNC 3中的MI300X相比,ADNC 4中的MI355X通过减少单个XCD中的CU和某些单元的CUS来提高性能,但以高时钟频率减少了性能差距。在计算低预测的关键指标中离子矩阵,ADNC 4将CU的每个矩阵的性能加倍,而FP6的精度性能与传输多处理器NVIDIA B200(SM)相同。但是,在8和16位数据类型之间,NVIDIA仍然保持单个周期收率的优势。但是,由于CUS的数量和频率很高,AMD在共同的矢量计算中保持绝对潜在客户(例如FP32)。单个CU仍然提供128 FP32计算机管道,其一般性能远高于NVIDIA Blackwell Architecture。 ADNC 4的核心改进之一是增加本地数据交换(LDS)的能力和带宽。 SUS容量从64 KB增加到160 KB,读数带宽增加了一倍,达到每个周期的256个字节,并且添加了“ transpos读取”指令,以优化矩阵乘法的命中式访问效率。 NVIDIA的共享内存具有单个缓存和缓存灵活性的出色容量(最多228 kb的共享内存)。 だったります)AMD弥补了中央级别缺乏存储,完全容量为40 MB LDS GPU(B200约为33 MB)。在视频内存方面,MI355X已更新为HBM3E技术,总计8TB/SY带宽的容量为288 GB,大大超过7.7tb/sy 180GB NVIDIA B200。在大型数据计算中,尤其是当AMD的体系结构可以减少数据交换中的延迟时,尤其是当AI模型超过内存容量时,这一优势尤其重要。媒体认为,AMD的ADUNC 4继续通过优化而不是破坏性的创新来整合收益,以及Zen的迭代逻辑。Strategy专注于增加计算机规模和内存带宽,同时瞄准AI缺陷。必须被认为重要的媒体是在提高性能方面的AMD和NVIDIA之间的差异。虽然AMD基于“大芯片 + Gran Cache”模型,但NVIDIA对该禁令更加关注视频记忆的单个核的昏迷和效率。